
Improving Single Token Compression for Retrieval Augmented Generation
Authors: Mansheel Agarwal, Shyam Varahagiri, Earl Ranario, Akanksha Giliyal, Horacio Contreras
Traditional retrieval methods like RAG or xRAG compress a single document to just one token, leading to hallucinations. We propose an enhanced approach that generates multiple synthetic queries with the same intent but different perspectives using an LLM, then uses ensemble scoring to rerank and compress the highest-scoring document into a single token. We also introduce a multi-document token generation method that aggregates embeddings from top-ranked documents for richer context.
Background
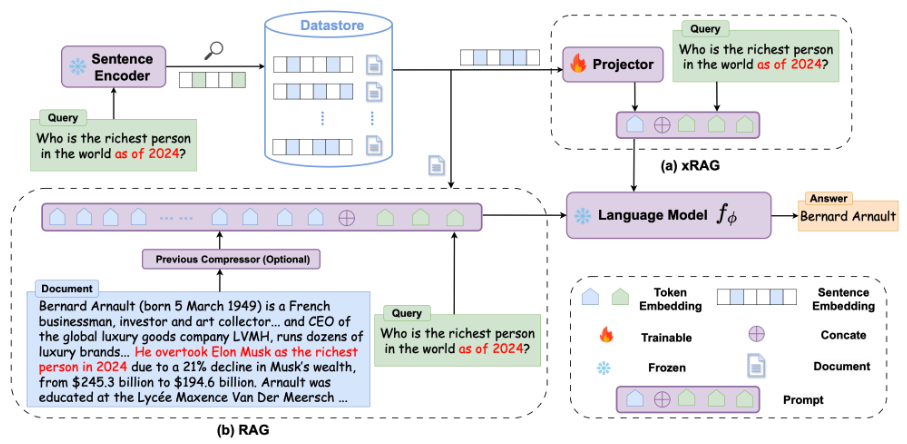 Figure 1: The original xRAG method compresses document embeddings into a single token for the language model, reducing memory and compute overhead over standard RAG but losing contextual richness.
Figure 1: The original xRAG method compresses document embeddings into a single token for the language model, reducing memory and compute overhead over standard RAG but losing contextual richness.
xRAG compresses a retrieved document into a single token before passing it to the reader model. While this dramatically reduces memory and compute overhead compared to standard RAG, it is prone to hallucinations when the wrong document is retrieved — and it cannot handle queries that require information from multiple documents.
Method
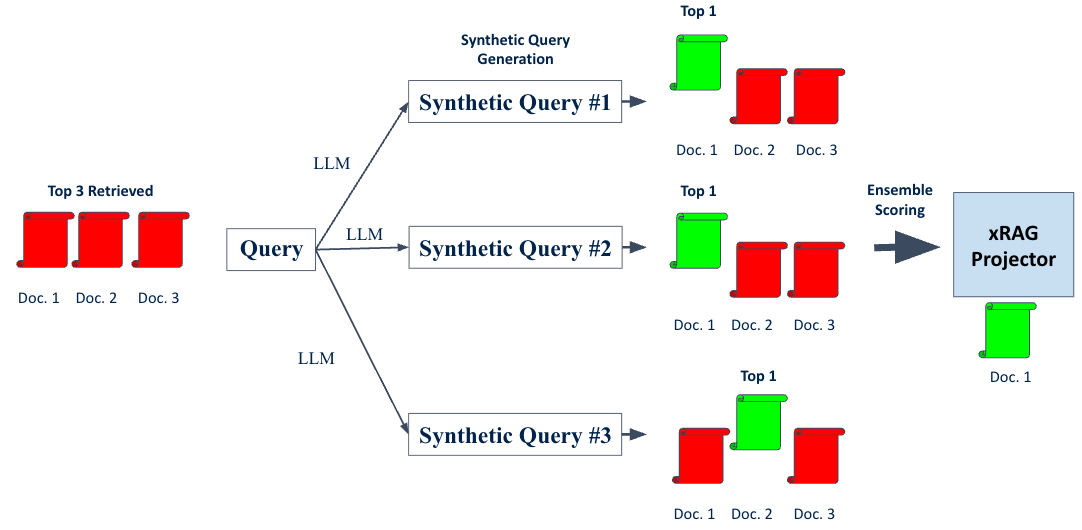 Figure 2: Our method generates multiple synthetic queries from the original query, retrieves top documents for each, and uses ensemble scoring to select the best document before xRAG compression.
Figure 2: Our method generates multiple synthetic queries from the original query, retrieves top documents for each, and uses ensemble scoring to select the best document before xRAG compression.
Our approach consists of three key components:
- Synthetic Query Generation — LLaMA-7B generates k query variants with the same intent but different perspectives, broadening document retrieval coverage.
- Ensemble Scoring — Retrieved documents are reranked by aggregating relevance scores across all synthetic queries, reducing the chance of selecting an incorrect document.
- Token Compression — The highest-scoring document is compressed into a single token via the xRAG projector and passed to the reader model (Mistral-7B).
 Figure 3: Prompt template used to generate k synthetic query variations.
Figure 3: Prompt template used to generate k synthetic query variations.
Experiments
Dataset: TriviaQA with LLaMA-7B-generated distractor documents to simulate noisy retrieval conditions. Performance is measured via Exact Match (EM).
Results
| k (synthetic queries) | Exact Match | Δtime (s) |
|---|---|---|
| 0 (baseline) | 0.51 | — |
| 1 | 0.51 | +7 |
| 5 | 0.51 | +33 |
| 10 | 0.52 | +62 |
| 15 | 0.51 | +78 |
| 20 | 0.53 | +80 |
The best single-document result is achieved at k=20 (EM=0.53). The multi-document token generation method aggregates embeddings from the top-n documents, achieving a total processing time of 15.6s vs. 43.2s for the original xRAG — improving both accuracy and efficiency simultaneously.
Embedding Analysis
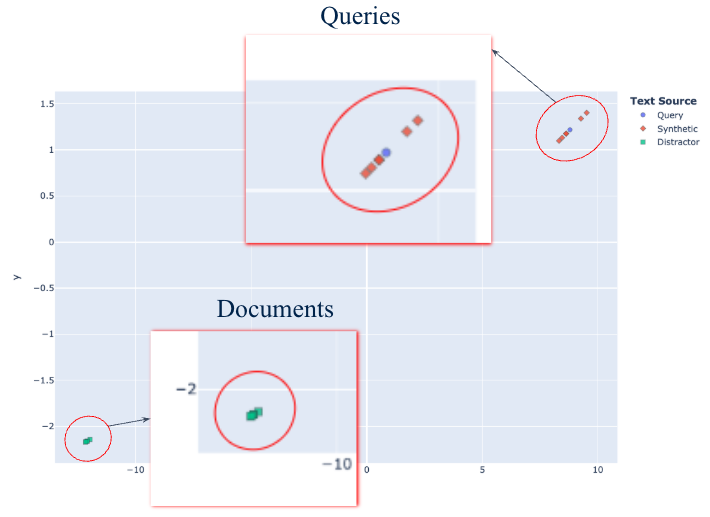 Figure 4: paCMAP visualization of query, synthetic query, and document embeddings. Synthetic queries occupy the same embedding space as the original query (linear distribution), while document embeddings cluster narrowly — suggesting room to improve retrieval diversity.
Figure 4: paCMAP visualization of query, synthetic query, and document embeddings. Synthetic queries occupy the same embedding space as the original query (linear distribution), while document embeddings cluster narrowly — suggesting room to improve retrieval diversity.
Conclusion
Our methods improve both accuracy and efficiency of xRAG, setting new benchmarks in retrieval-augmented generation. Future work will focus on hybridizing the multi-document and multi-query approaches and building a custom structured query-answer dataset better suited to these retrieval strategies.
References
-
Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Küttler, H., Lewis, M., Yih, W., Rocktäschel, T., Riedel, S., & Kiela, D. (2020). Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. NeurIPS 2020.
-
Cheng, X., Wang, X., Zhang, X., Ge, T., Chen, S., Wei, F., Zhang, H., & Zhao, D. (2024). xRAG: Extreme Context Compression for Retrieval-Augmented Generation with One Token. arXiv preprint.