
Are vision-language models ready to zero-shot replace supervised classification models in agriculture?
Authors: Earl Ranario, J. Mason Earles
Vision-language models (VLMs) are increasingly proposed as general-purpose solutions for visual recognition tasks, yet their reliability for agricultural decision support remains poorly understood. We benchmark a diverse set of open-source and closed-source VLMs on 27 agricultural image classification datasets from the AgML collection, spanning 162 classes and 248,000 images across plant disease, pest and damage, and plant and weed species identification. Overall, these results indicate that current off-the-shelf VLMs are not yet suitable as standalone agricultural diagnostic systems, but can function as assistive components when paired with constrained interfaces, explicit label ontologies, and domain-aware evaluation strategies.
![]()
Key Highlights
- VLMs Underperform Supervised Models: Current zero-shot vision-language models (VLMs) consistently fail to match the performance of supervised, task-specific models like YOLO11 in agricultural classification tasks.
- Prompting Format is Critical: Constraining a model’s output via multiple-choice question answering (MCQA) yields significantly higher accuracy than open-ended questions, as it reduces errors related to recall and naming ambiguity.
- Evaluation Methodology Affects Results: Using an LLM-based semantic judge to evaluate responses—rather than simple string matching—captures correct answers that use synonyms, which can significantly change model rankings and reported performance.
- Task-Specific Challenges: Identifying pests and crop damage is consistently more difficult for VLMs than classifying plant and weed species, likely due to the need for contextual information (like geography or management history) that is often missing from single images.
Datasets Overview

Figure 1. Overview of all datasets used from the AgML collection.
Prompt Overview
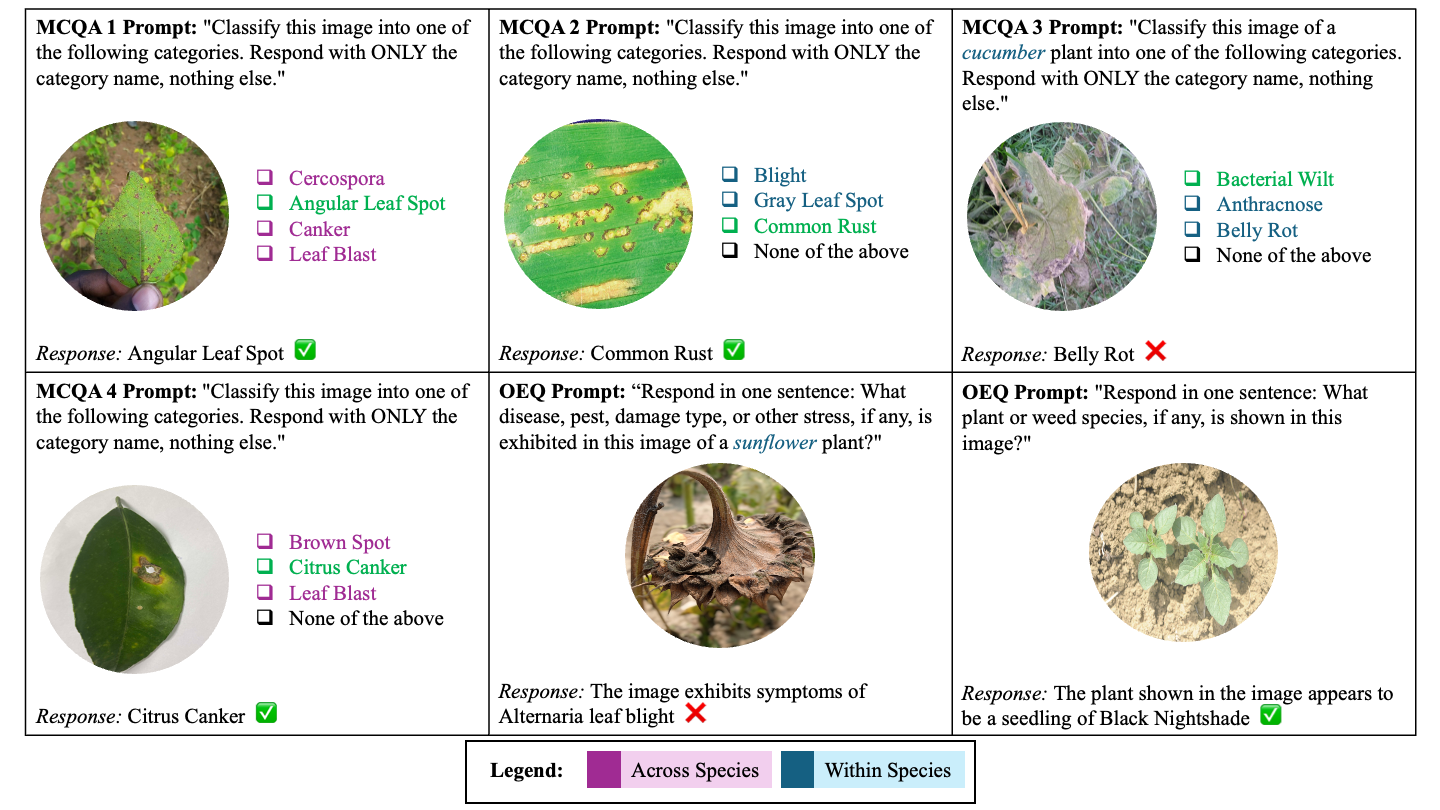
Figure 2. Overview of the prompting methodologies compared in this study.
LLM Judge Overview


Figure 3. Overview of the LLM-based semantic judge used to evaluate responses.
Overall Results
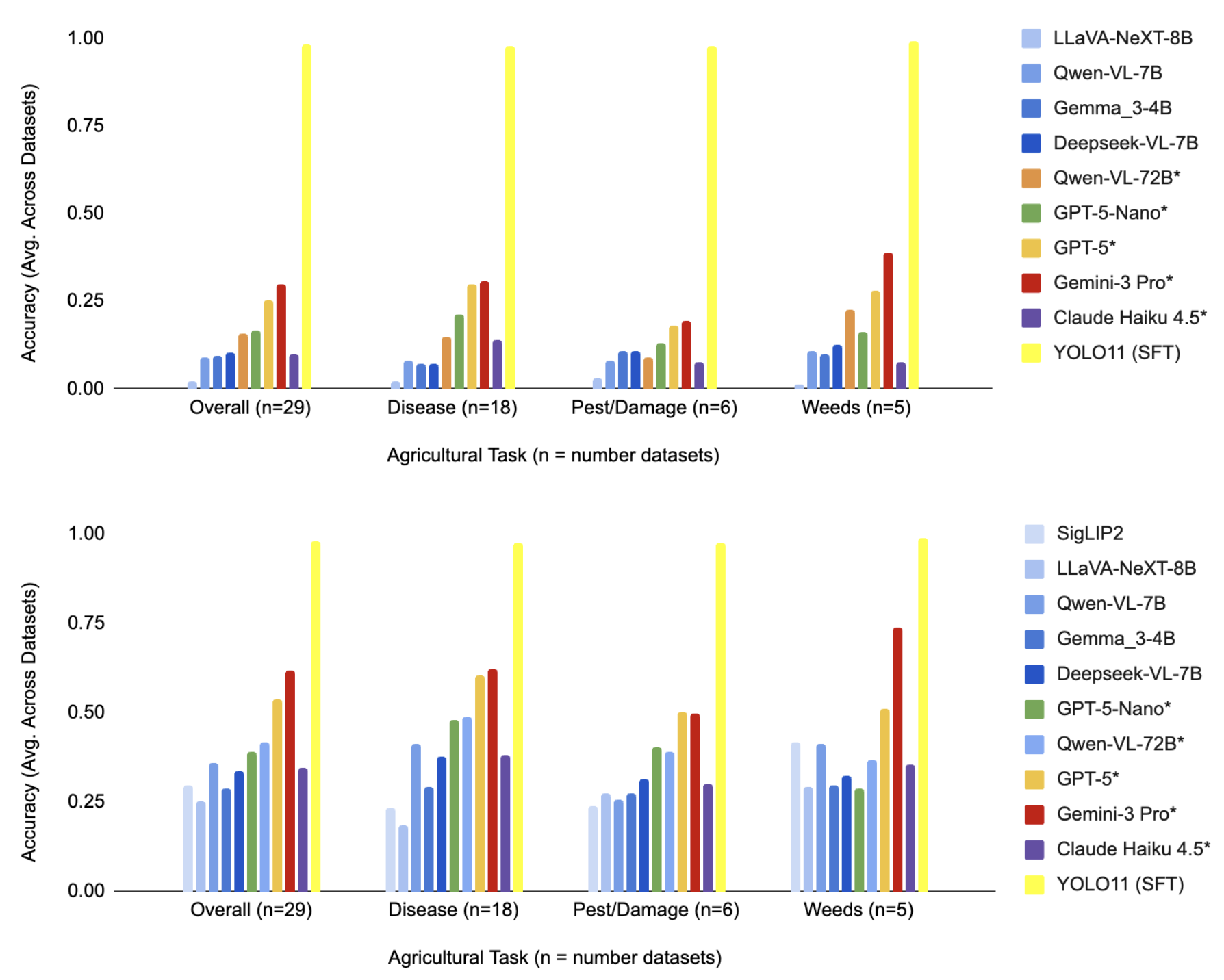
Figure 5. Overall performance results across various models and tasks.
Model and Judge Analysis
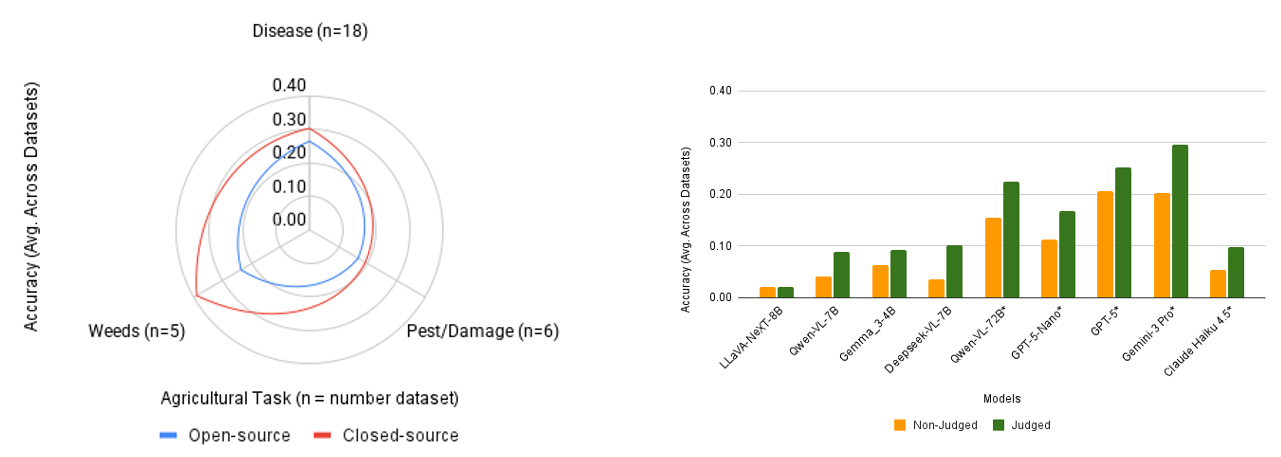
Figure 6. Best performing models and the impact of the semantic judge on results.
Citation
If you find this work or the AgML datasets useful, please cite our paper:
@misc{ranario2025visionlanguagemodelsreadyzeroshot,
title={Are vision-language models ready to zero-shot replace supervised classification models in agriculture?},
author={Earl Ranario and Lars Lundqvist and Heesup Yun and Brian N. Bailey and J. Mason Earles},
year={2025},
eprint={2512.15977},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2512.15977},
}