
AGILE: A Diffusion-Based Attention-Guided Image and Label Translation for Efficient Cross-Domain Plant Trait Identification
Authors: Earl Ranario, Lars Lundqvist, Heesup Yun, Brian N. Bailey, J. Mason Earles
Semantically consistent cross-domain image translation facilitates the generation of training data by transferring labels across different domains, making it particularly useful for plant trait identification in agriculture. However, existing generative models struggle to maintain object-level accuracy when translating images between domains, especially when domain gaps are significant. In this work, we introduce AGILE (Attention-Guided Image and Label Translation for Efficient Cross-Domain Plant Trait Identification), a diffusion-based framework that leverages optimized text embeddings and attention guidance to semantically constrain image translation. AGILE utilizes pretrained diffusion models and publicly available agricultural datasets to improve the fidelity of translated images while preserving critical object semantics. Our approach optimizes text embeddings to strengthen the correspondence between source and target images and guides attention maps during the denoising process to control object placement. We evaluate AGILE on cross-domain plant datasets and demonstrate its effectiveness in generating semantically accurate translated images. Quantitative experiments show that AGILE enhances object detection performance in the target domain while maintaining realism and consistency. Compared to prior image translation methods, AGILE achieves superior semantic alignment, particularly in challenging cases where objects vary significantly or domain gaps are substantial.
![]()
Notice: You can find more information and references in the published paper.
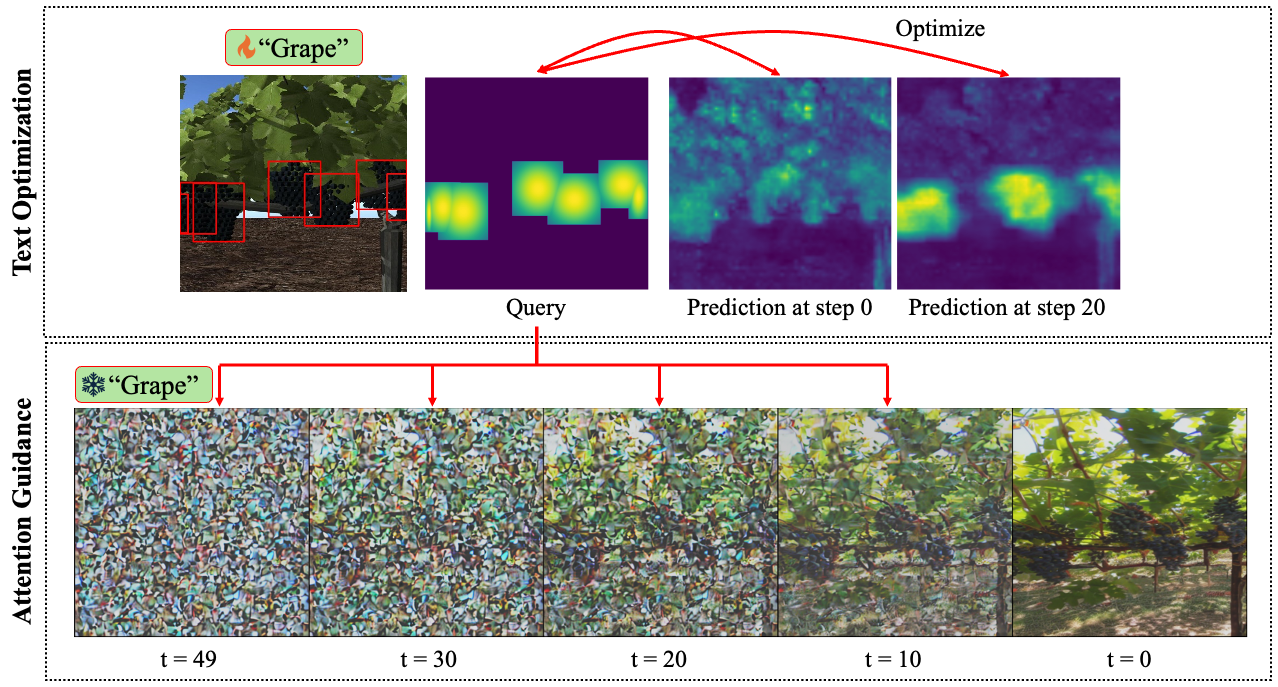
Figure 1. Overview.
Introduction
Computer vision is used in a wide range of agricultural tasks such plant phenotyping, disease detection and yield identification. These tasks typically involve the identification of plant-specific traits or characteristics through the use of deep learning models. However, the performance of these deep learning models are limited to the availability of labeled data. Although gathering data in the field through remote sensing tasks is necessary to capture the existing status of the plants, the limitation lies in manually labeling these specific traits of interest.
There has been an emphasis on expanding public agricultural datasets, such as the machine learning library AgML, but it is still not adequate enough to address the complex domain scenarios in agriculture. However, recent generative AI methods have pushed possibilities to generate training data for specific use cases. In this research, we utilize synthetic data generated from Helios and domain-translate them to make it look real.
This paper studies how to efficiently utilize existing labeled images (synthetic images) to improve semantic accuracy in image-to-image translation tasks, specifically for plant trait identification. We propose a diffusion-based method Attention-Guided Image and Label Translation for Efficient Cross-Domain Plant Trait Identification (AGILE), which utilizes existing pretrained diffusion models and public agricultural datasets to generate labeled images for specific domains. The idea is to use labels generated for supervised tasks to gain object domain knowledge represented by text labels. Through this, we should be able to find semantic correspondences between the source and target domain and guide it to desired regions.
Our contributions include:
- Images collected in real-world settings often lack accompanying text descriptions and semantic alignment with text inputs. By optimizing prompt embeddings, we leverage existing labeled images to emphasize regions of interest, improving semantic knowledge. This allows us to have text-image correspondence with few labeled images.
- With semantically-aware, optimized prompt embeddings, we can control object semantics in the target domain through attention guidance during the de-noising process of a diffusion-based model. This allows labels to be transferrable from the source to target domains
- We compare the performance between the source (synthetic), target (real) and generated data for object detection tasks.
Current Domain Translation Methods
There are many existing and improving generative methods for image-to-image or text-to-image translation tasks. Typically, they are built upon Generative Adversarial Networks (GANs) or probabilistic models such as Denoising Diffusion Probabilistic Models (DDPM). More recently, Stable Diffusion by Stability AI is able to generate very complex scenes.
Our approach tries to solve the limitations in generative AI within the agricultural domain. First, for most diffusion-based models, training a model that can translate an image from one domain to another requires paired images, which is difficult to obtain. Second, images collected in the field do not come with text descriptions, unless standardized and defined by the user. Third, the generated images may not be semantically accurate or not contain the desired object.
Method Overview
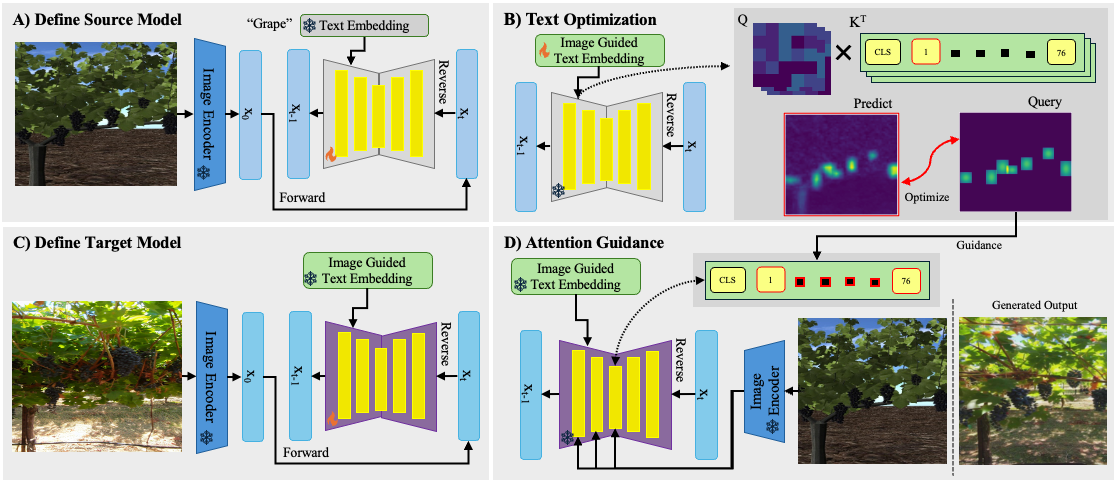
Figure 2. Proposed method.
We build the proposed method on top of ControlNet, which enables conditional control of pretrained diffusion models by incorporating external control signals during the generation process. Our method first includes finding semantic correspondences between source and target images using pretrained diffusion models. In order to do that, we first optimize text embeddings using a query attention map generated from the labels of the source images. This allows us to have text-image correspondence without the need for paired images. Then, we use the optimized text embeddings to highlight regions of interest in the target domain. We further guide the attention maps to highlight the desired regions using the same set of query attention maps. This allows us to control the semantics of the target image through attention guidance during the denoising process of a diffusion-based model.
Text Optimization
Images collected in the field do not come with a paired text description. If we want to “edit” the attention maps to “guide” the objects in the correct location within the image, we will need some semantic correspondence between the text and image pairs. To do this, we optimize the provided text embeddings using the labeled synthetic images.

Figure 3. Original work: https://github.com/ubc-vision/LDM_correspondences
As seen in Figure 1, certain text descriptions attend to different regions of the attention map. These attention maps are derived from the cross-attention between the image and text embeddings. But, out-of-the-box, these text descriptions do not automatically attend nicely to these regions, we will need to optimize for that.
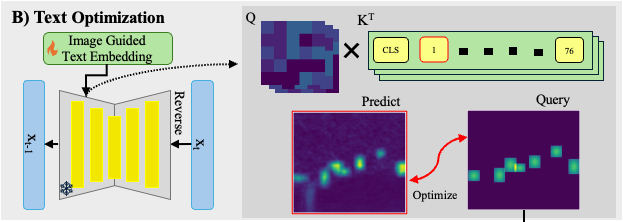
Figure 3. Text optimization using a query attention map.
We create a query attention map from the labeled bounding boxes from the synthetic images. Then, we optimize using a MSE loss function between the predicted and query attention map, therefore altering the text embedding.
Cross-Attention Guidance
Content preservation through cross-attention guidance involves maintaining the semantics of an image before and after diffusion translation by ensuring that the text-image cross-attention map remains consistent. During the denoising process, we take the attention maps from the first three layers and edit them to attend to the correct location in the generated image. Since we used a CLIP encoder, we edit token 1 to 76 (ignoring the class token). As seen in Figure 4, we take the frozen text embedding, edit the specified attention maps, and obtain the final generated image.
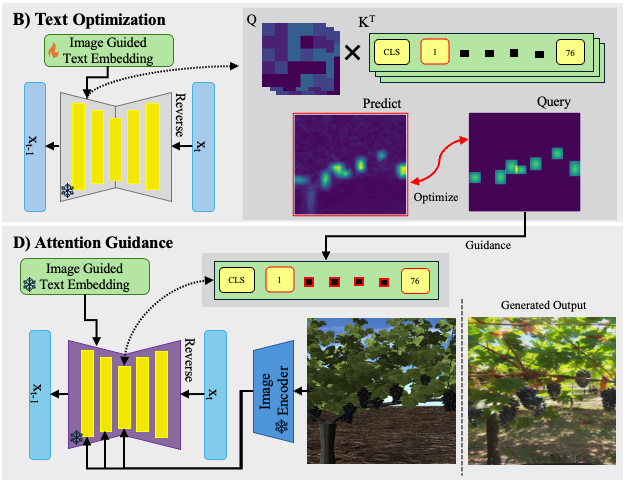
Figure 4. Attention guidance using query attention map.
The figure below (Figure 5) is a rough example of how the editing works. We take the flattened query map and add it to each token. Afterwards, each token can be scaled by beta to amplify the edit if needed.

Figure 5. Rough edit example.
Results

Figure 6. Results.
Our experimental results demonstrate that AGILE consistently outperforms existing image translation methods across multiple datasets. The quantitative results highlight improvements in object detection performance, while the qualitative comparisons show enhanced realism and consistency in generated images.
However, our approach still faces challenges when translating small objects or generalizing to unseen examples. Additionally, existing domain gaps such as perspective, brightness, and plant type are not fully addressed during the diffusion process. While the domain-translated images generated by AGILE may not completely surpass the performance of using real, labeled target images, they can still provide valuable information for pretraining a backbone model. This pretraining can enhance the model’s ability to extract relevant features, which can then be further fine-tuned using a limited set of labeled images from the target domain. Future work will focus on extending our method to incorporate multi-class guidance through enhanced text embeddings and improving robustness to various domain gaps. Furthermore, we will explore more efficient optimization techniques to enhance performance and generalization across diverse agricultural datasets.